Sentiment analysis is a process that allows computer programs to understand if the opinion expressed in text is positive, negative, or neutral. When applied to content published online, both on social and traditional media channels, sentiment analysis can provide important business insights about public opinion and perception towards topics and brands.
Whether you’re monitoring how an ad campaign or product launch performs, or if you’re tracking the fallout of a PR disaster, public perception is vital to brands’ and organizations’ media strategies.
Usually, sentiment analysis works by analyzing text at document-level, which means that an entire news story, product review, or social media post will be analyzed as one piece of text and one sentiment prediction will be made for that entire document.
While this can particularly useful in some use cases, there’s a problem with document-level sentiment analysis: most documents talk about more than one thing, and usually there is quite varied sentiment being expressed about each of these things. So using document-level sentiment analysis won’t always give you results that are granular enough to provide a true understanding in opinion mining.

So if you want to extract more accurate and detailed insights from the data that matters to you, you really need to dig in deeper than document-level. To let you do this, we’ve built our new Entity-level Sentiment Analysis endpoint, or ELSA.
What does Entity-level Sentiment Analysis do?
After recognizing the entities mentioned in a document and which parts of the document are talking about each entity, ELSA accurately predicts the sentiment expressed about each individual entity in the text, even when the sentiment about each is different.
For example, here’s a sentence with three different sentiments expressed about three different entities - “Jeb Bush is ok, but lyin' Ted Cruz is the worst. He'll never be as great as your president, Donald J Trump”. While document-level sentiment analysis would return a single result (probably “negative”), we can clearly see that there is different sentiment directed toward each entity mentioned in this piece of text.
This is where ELSA comes in. Take a look at the results for this sentence:
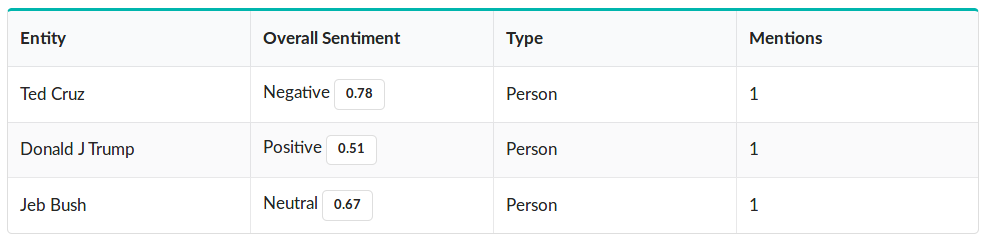
You can see that the ELSA endpoint has correctly identified each entity mentioned, and accurately predicted which sentiment is being express about each. When we tweak the input sentence to “Jeb Bush is phenomenal, but Ted Cruz is even better. I wish that I, Donald J Trump, could be half the man they are”, you can see this reflected in the results:
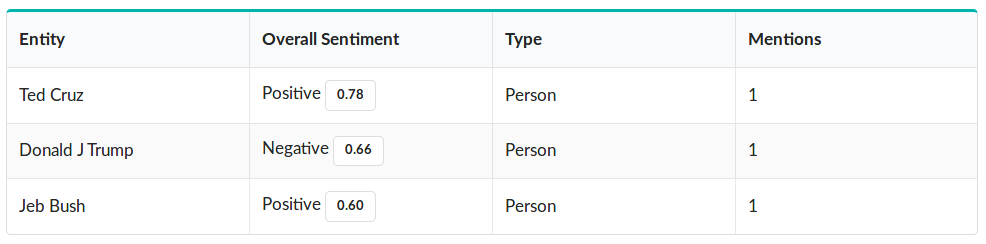
This is particularly valuable when we want to know how specific people, organizations, or things are being mentioned in text that matters to us. Let’s take a look at how Entity-level Sentiment Analysis is particularly useful on a larger dataset - stories we gathered with the News API - using a real world example.
Using Entity-level Sentiment Analysis to supercharge your media monitoring insights
Recently, Google held their annual I/O conference, where the company announces upcoming product launches and updates. Knowing how these product announcements were received by the media is valuable information, since it can help us predict which products will be the next Gmail, and which will be the next Google Glass.
Using the News API, we gathered just over 8,500 stories mentioning the conference. You can see that a document-level sentiment analysis shows us that the coverage was generally good with 4,236 positive stories, 2,251 neutral ones, and 2,095 stories expressing negative sentiment.
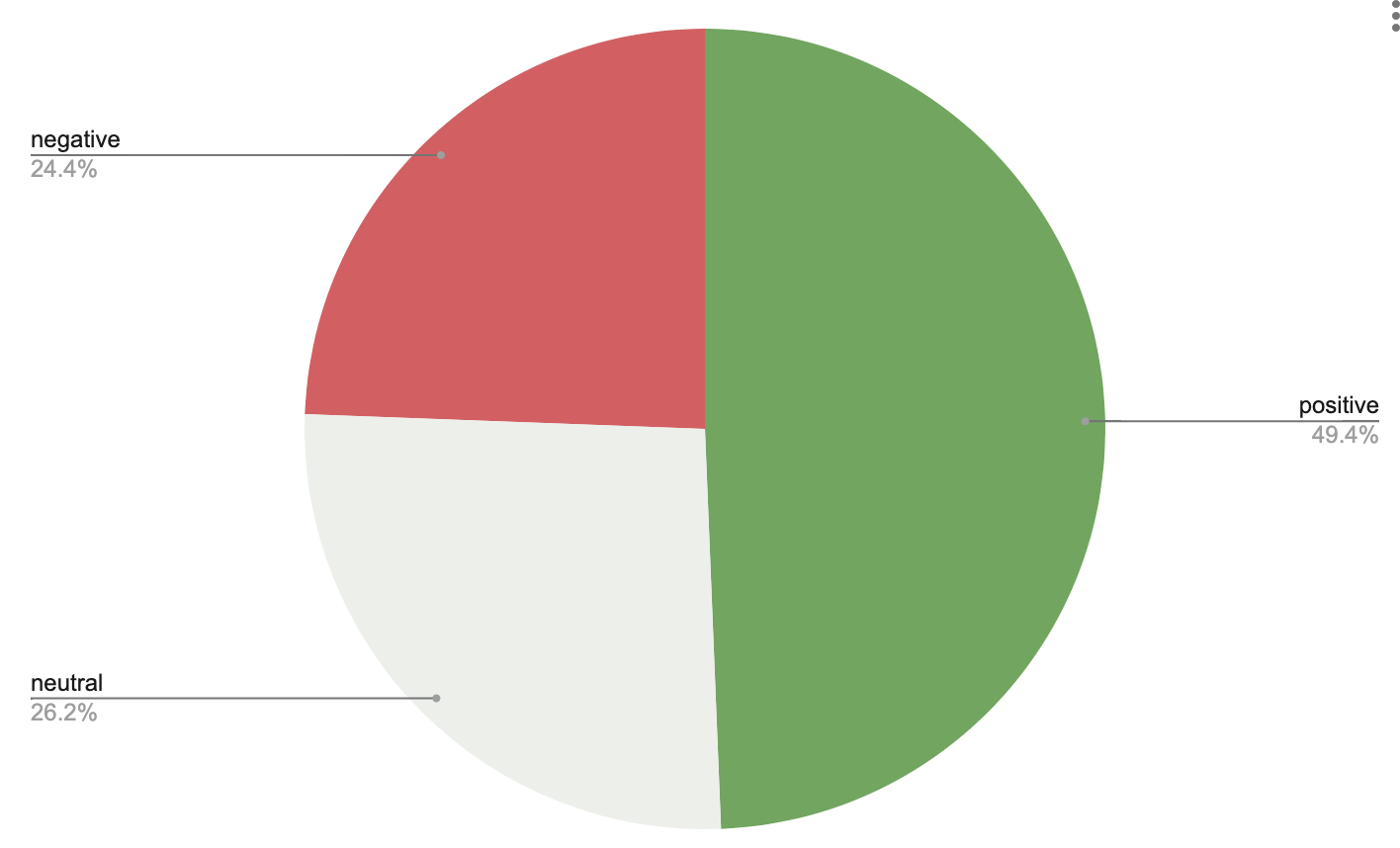
Knowing that the media were generally positive about the conference is valuable information. But here’s a problem: since so many product announcements are made at the conference, most of the news stories covering the event will mention more than one product. This means that the truly valuable insights are buried inside the documents, and we need a tool to analyze the entities instead of simply the documents.
Now, using ELSA, we can extract much more granular insights, and see how every person, organization, and thing was being talked about within this coverage.
To get an overview of how granular entity-level results are than document-level, take a look at the bubble chart below, showing the sentiment attached to every entity mentioned in the 8,500 stories. The colour of the each bubble corresponds to the average polarity expressed about that entity, and the size corresponds to the number of stories in which it is mentioned (you might want to look at this in fullscreen mode to get the best out of it).
We could spend hours looking into this data, comparing how different products, brands, and other things were covered. But for a simple example, we’re going to look into something that interests us here in the AYLIEN office - Artificial Intelligence research and the consumer products that companies are building with it.
Diving into Entity-level Sentiment Analysis data from coverage of the Google I/O conference
We looked at a sample of 20 entities that covered AI research topics, companies conducting and monetizing this research, and the products that will be powered by it. On the table below, you can see how many times each entity was mentioned in the 8,500 stories, as well as the average sentiment expressed about each entity. Scoring closer to 1 indicates positive coverage, while closer to -1 is negative, and 0 is neutral.
Sentiment expressed about 20 AI-related entities in the 8,500 stories mentioning Google I/O, sorted by popularity:
| Entity | Stories mentioning | Polarity | |
|---|---|---|---|
| Deep_learning | 142 | 0.52 | |
| Machine Learning | 21 | 0.47 | |
| Amazon_(company) | 1630 | 0.39 | |
| Speech_synthesis | 11 | 0.27 | |
| NLP | 21 | 0.26 | |
| Apple_Inc. | 1547 | 0.24 | |
| Artificial_intelligence | 1857 | 0.23 | |
| AVERAGE DOCUMENT POLARITY | 8,500 | 0.22 | |
| Google_Play | 296 | 0.16 | |
| Google_Fiber | 14 | 0.16 | |
| DeepMind | 52 | 0.15 | |
| Alphabet_Inc. | 275 | 0.15 | |
| Sundar_Pichai | 152 | 0.14 | |
| Google Duplex | 124 | 0.11 | |
| Google Assistant | 326 | 0.1 | |
| YouTube | 920 | 0.07 | |
| Gmail | 203 | 0.06 | |
| 7848 | 0.05 | ||
| Google_Maps | 195 | 0.04 | |
| 2661 | -0.04 |
It’s highly interesting to see that even though they are covered less, the scientific entities garnered the most positive coverage, noticeably more positive than the products they are powering.
We found Google’s Duplex demo interesting here in the office so we decided to look into the media reaction to it’s launch. If you follow anything related to AI you’ve probably seen it in action, Duplex is an automated system that can make phone calls to people and carry out tasks like making reservations and ordering food. There was some discomfort expressed online about how the system can fool a human into thinking they are speaking with another person instead of a bot.
When we look into the ELSA results from stories where Google Duplex was mentioned, we can see the other entities that were mentioned in these stories, and the sentiment that was expressed towards them. Below are the 20 most-mentioned entities:
Sentiment towards other entities and concepts mentioned alongside Google Duplex, sorted by number of mentions:
| Entity | Stories Mentioning | Polarity | |
|---|---|---|---|
| Artificial_intelligence | 153 | 0.17 | |
| 124 | 0.13 | ||
| I/O | 71 | 0.25 | |
| Call_centre | 36 | 0.13 | |
| Mountain_View_California | 29 | 0 | |
| Sundar_Pichai | 28 | 0.11 | |
| Amazon_(company) | 26 | 0.46 | |
| Apple_Inc. | 19 | 0.29 | |
| Fox_Broadcasting_Company | 19 | 0 | |
| Ethics | 17 | -0.23 | |
| Turing_test | 17 | 0 | |
| Microsoft | 17 | 0.24 | |
| MacBook | 15 | 0.74 | |
| 14 | 0.09 | ||
| Manhattan | 13 | 0.06 | |
| San_Francisco | 12 | 0.56 | |
| IBM | 12 | 0.53 | |
| India | 11 | -0.04 | |
| 11 | -0.04 |
You can see that, predictably, the most-mentioned entities and concepts in these stories are Google and Artificial Intelligence, but there are two things that jump out at us from this table.
First, ethics was mentioned in a far more negative tone than any other entity, reflecting the nervousness with which many people greeted the demo.
Second, you can see that Amazon and Alexa are mentioned in a much more positive tone than Google, possibly reflecting a preference in the journalists’ opinions.
Did Amazon and Alexa get better coverage than Google and Duplex in the stories mentioning Google I/O?
We noticed in the ELSA results above that Amazon and Alexa received positive coverage stories mentioning Duplex. We thought this was quite interesting, since it suggests that the press is very positive about Amazon’s advances in AI.
To look into this idea, we looked at the overall sentiment towards in the stories towards Amazon and Google, and we then compared this with the sentiment towards each company in stories where each company’s flagship AI assistants were also mentioned.
Here are the results about Amazon:
Amazon
Overall sentiment in all stories0.38
Sentiment in stories that also mention Alexa0.52
And here are the results about Google:
Overall sentiment in all stories0.05
Sentiment in stories that also mention Duplex0.13
You can see two interesting points. First, Amazon is talked about more positively than Google across the board, but also that each company is talked about more positively when their AI-powered assistants are mentioned. In other words, having your AI products covered in the press gives these companies an “AI bump” in positive coverage.
Using document-level sentiment analysis, this insight would have escaped us, but ELSA allows us to dive into important text content and extract much more granular insights. If you want to dig deep into data that is valuable to you, you can analyze 1,000 pieces of text per day for free to try it out. Just click the link below to sign up!
Note: as the ELSA endpoint carries out a significantly larger amount of work under the hood, every one call to this endpoint will count as three hits toward your allowance.

Related Content
-
 General
General16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
-
 Product
Product15 Mar, 2023
Introducing an even better Quantexa News Intelligence app experience
Ross Hamer
4 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.