This blog is part of a series, AYLIEN NEWS API: A Starter Guide for Python Users. You can view the Jupyter Notebook learner document here.
The volume and incessant nature of news is overwhelming - that’s why large organisations need news intelligence platforms if they are to practically leverage the power of news to their benefit.
In the last blog in this series, we reviewed how at AYLIEN we ingest millions of news stories into our ecosystem everyday. But high volumes of news content are of no use if we don’t know what it means at scale and we can’t find what we need, when we need it. That’s why we use machine learning and natural language processing (NLP) to structure, enrich and tag those documents, making them easily searchable and readily processable.
In this blog, we’ll go through the various methods you can use to refine your News API query to identify the news that is significant to your business.
Using Keyword Search with Time Parameters
One of the most basic queries we can perform on AYLIEN’s News API is searching for keywords. This is akin to using a search engine to find mentions of a word across AYLIEN’s database of news.
Needless to say, if we don’t define any time limitations, the volume of news stories that meet our keyword search criteria could be massive. With this in mind, it is best to define as precise a time window as possible to cut down the volume of stories that meet your needs.
Boolean Search
Keywords are a good starting point, but what if we wanted to identify the presence of two keywords? What if we wanted to identify stories that mentioned two keywords but also did not mention another keyword? Or what if we wanted to return stories that met one keyword criteria or another?
Boolean search allows users to combine keywords with operators such as AND, NOT and OR to refine our search to meet our needs. For example, we could search for stories relating to Apple Inc. by searching for the “apple” keyword; we could then extend this to “apple NOT fruit” in order to explicitly state we are not interested in articles that mention apple and fruit.
Entity Search
While keyword searches can be useful in scenarios where we are interested in mentions of quite unique terms, over reliance on keyword-based search is problematic because they are prone to returning irrelevant results due to lexical ambiguities (e.g. Apple vs apple). Working around this problem requires lengthy, complex queries that can take a huge amount of time to create, update and maintain, which negatively affects productivity.
Thankfully, AYLIEN’s News API provides a solution. Using machine learning and natural language processing, our models identify and tag entities in stories to enrich our documents with data points that enhance search and usage capabilities. This means that people, places, companies and concepts will be tagged with unique IDs, which makes the task of finding them much, much easier.
Learn more about the effectiveness of using entities instead of keywords here.
Categorical Search
We can see that keywords and entities help us identify stories that mention the items we’re interested in, but unless we elaborate our keyword search or include lists of entities, we can’t be sure of the context of the story. For example, if we search for the entity Facebook, we could get a myriad of stories relating to entertainment, data privacy or business.
AYLIEN’s NLP enrichment classifies news stories into news categories such as business, economics and finance, crime, politics, sport, entertainment and many others. In fact, we use two news taxonomies to help our users isolate the news types that really matter to them and can choose between utilising IPTC and IAB QAG models.
For instance, if I was interested in business stories relating to Facebook share price, I could define a news category parameter of stocks as well as the Facebook entity. Similarly, if I was interested in tracking country risk stories worldwide, I could limit to crime, civil unrest, conflict and war and terrorism categories without needing to specify any keywords or entity types.
Refining your Query - a Simple Example
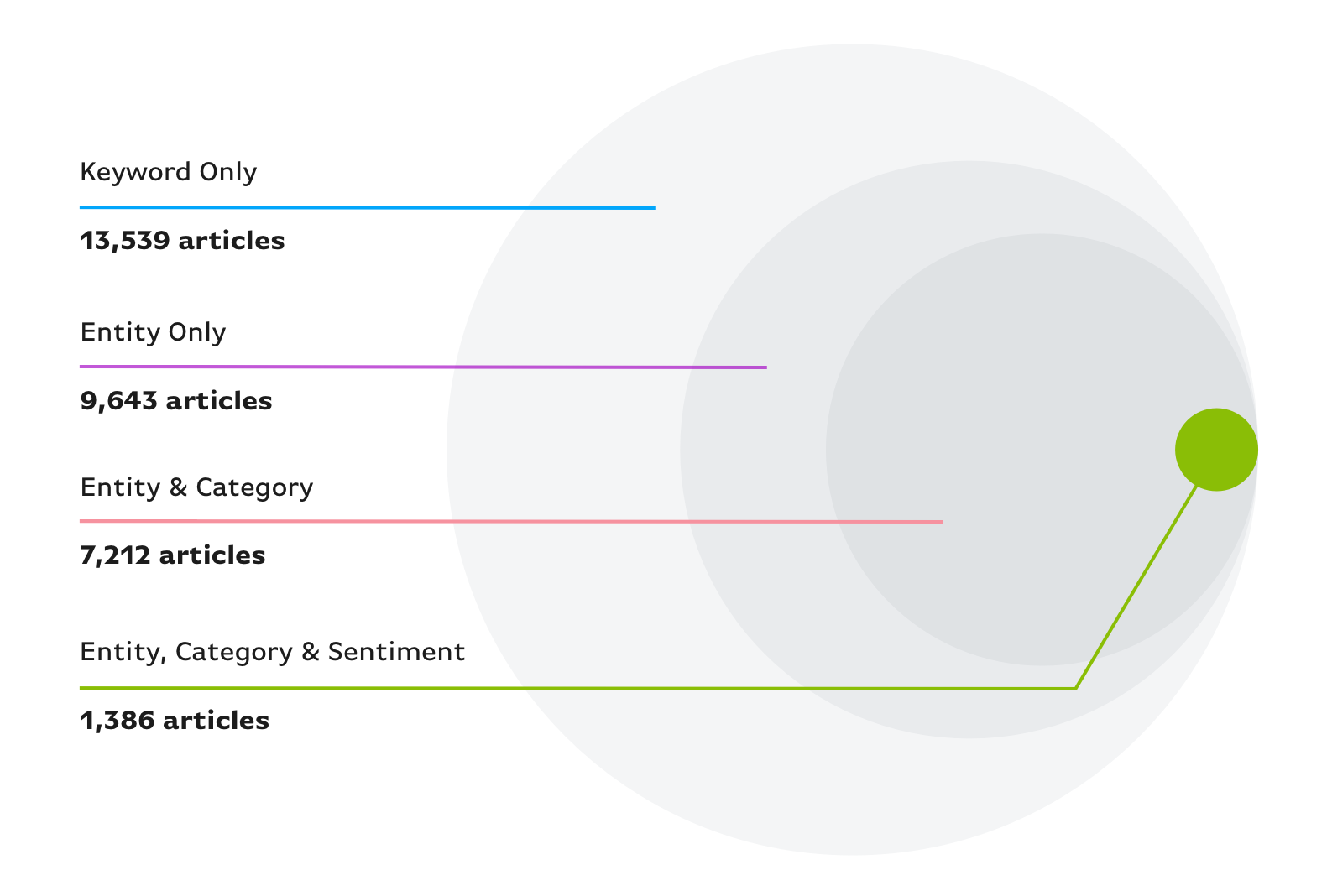
We can showcase how all these elements can combine to refine a query and isolate the stories that matter to your business. The chart below relates iterative stages of refining a query and the volume of stories they returned respectively.
As a proof of concept, we decided to pull negative business stories relating to Apple Inc for one random day. First, we searched for any stories that included the keyword “apple”, returning 13K stories. We amended this to search for Apple Inc using its unique entity ID, reducing the output to 10K. Next, we specified the category economy, business and finance, reducing the stories further to 7K.
Finally, we limited the search to documents that have been classified as having negative sentiment, resulting in a much whittled down number of 1.4K stories. Check out how we leverage sentiment in our next blog in the series.
In the next blog in the series, we’ll look at how to use the Timeseries endpoint to analyse macro level changes in news content over time.
This blog is part of a series, AYLIEN NEWS API: A Starter Guide for Python Users. You can view the Jupyter Notebook learner document here.
Other Blogs in the series:
Starter Guide 1: AYLIEN’s Story Object - a Primer on NLP Enrichment and How to Use it
Starter Guide 3: How To Use The News API Timeseries Endpoint
Starter Guide 4: How To Use The News API Trends Endpoint
Starter Guide 5: Starter Guide 5: How to Use the News API Clusters Endpoint

Related Content
-
 General
General16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
-
 Product
Product15 Mar, 2023
Introducing an even better Quantexa News Intelligence app experience
Ross Hamer
4 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.