Programming languages are the primary tool of the software development industry. Since the 1940’s hundreds of them have been created and a huge amount of new lines of code in diverse programming languages are written and pushed to active repositories every day.
We believe that a source code classifier that can identify the programming language that a piece of code is written in would be a very useful tool for automatic syntax highlighting and label suggestion on platforms, such as StackOverflow and technical wikis. This inspired us to train a model for classifying code snippets based on their language, leveraging recent AI techniques for text classification.
We collected hundreds of thousands of source code files from GitHub repositories using the GitHub API. Before training our model, the raw data had to be processed to remove and mitigate some unwanted characteristics of code found in the wild. The final classifier performance is pretty good, and you can find the results at the end of this post, along with some explanations about the model’s decisions.
Data
Programming languages were selected based on their prominence. Chart 1 shows the 49 most used languages on GitHub during the final quarter of 2014 [1]. This analysis only considers active repositories, i.e. repositories that had at least one code push during this period. We've added HTML and XML to the list, and even though one may not consider them as programming languages, they are still relevant to software development projects. SQL was added for the same reason.Chart 1 - Active Repositories We used the
GitHub API to retrieve repositories for a specific query language. The chart below shows the data shape after a few days of crawling. Thousands of repositories were inspected, but the ones with a size greater than 100mb were ignored to avoid spending too much time on downloading and preprocessing. We used the file extensions to label each sample with its programming language (i.e. file.php is a PHP source file). C# was the most abundant source code language, while Arduino was the least frequent among the repos we crawled. In order to avoid an unbalanced training set, we used 10,000 examples at most per class.Chart 2 - Crawled Files
Mixed Source Codes
Looking carefully at the raw data, we find some challenging behaviours and characteristics, which is not a big surprise given that this data is pulled out of actual arbitrary repositories. The most frequent one is mixed languages in a single file, which happens more often in languages used for web applications, such as JavaScript, HTML, CSS, PHP and ASP. The ASP snippet below, extracted from a .asp source file, illustrates how this happens.
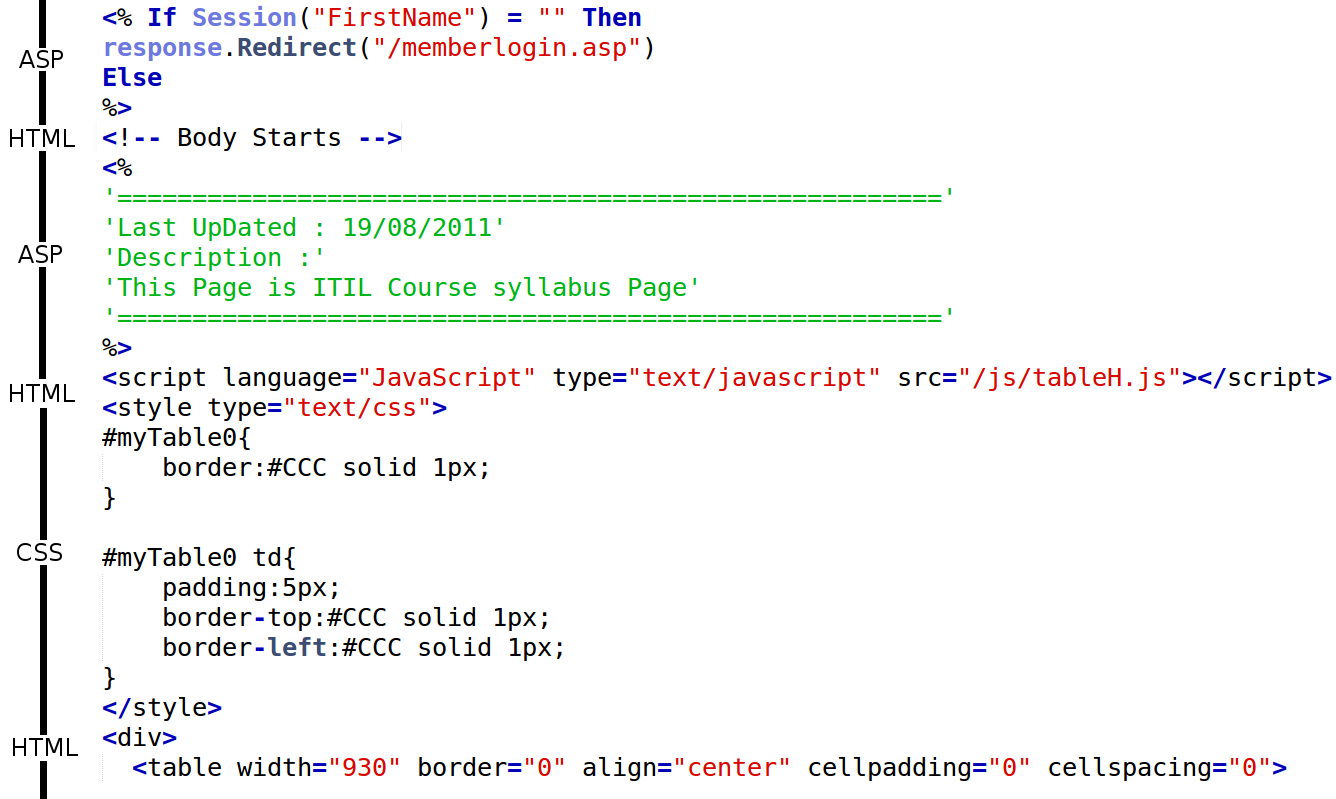
Figure 1 - Mixed Languages
In our case, we want to assign only one class to each document. So in case of mixed languages in a single source code file, we would like to keep only the snippets that belong to the primary language of the file (inferred from its extension), and strip everything else. To do so, we use known reserved words and expressions for each language. For instance, we know that all content between <%php and %> are php code, so if it is a .php file, we only keep this content, and remove everything else. In the same way it is easy to strip HTML tags from code using regex or built-in parsers in Python.
Another common feature found in these documents is embedded code snippets. For instance, in the JavaScript script below there is an embedded C snippet between the quotes. This is another type of mixed code that's very common. We mitigated this issue by replacing all content between the quotes by a placeholder (in this case we used strv as a string placeholder).
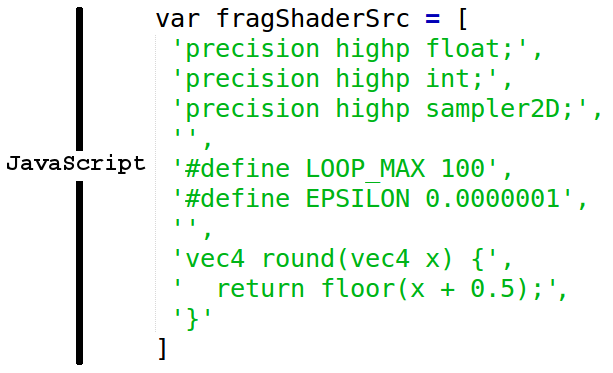
Figure 2 - JavaScript snippet with a “hidden” C code embedded
Tokenization
After the preprocessing step, which includes also escaping of newline and tab characters, we need to tokenize all our text. It is very important to retain all the code syntax information during this step. We used the [w']+|[""!"#$%&'()*+,-./:;<=>?@[]^_`{|}~""\] regex to extract our tokens. After this step the data is ready for training.
Python
print "This is using getsize"
for root, dirs, files in os.walk('/tmp'):
print root, "consumes"
Tokenized
print strv for root, dirs, files in os.walk(strv): print root, strv
Pre-processed
['print', 'strv', 'for', 'root', ',', 'dirs', ',', 'files', 'in', 'os', '.', 'walk', '(', 'strv', ')', ':', 'print', 'root,', '"', 'strv']
The Model
Recently, Convolutional Neural Networks (CNNs) have gained popularity for handling various NLP tasks. For text classification in particular, deep learning models have achieved remarkable results [2, 3]. Our model uses a word embedding layer followed by a convolutional layer with multiple filters, a max-pooling layer and finally a softmax layer (Figure 3). We used a non-static and randomly initialized embedding layer, so the vectors were trained from scratch.
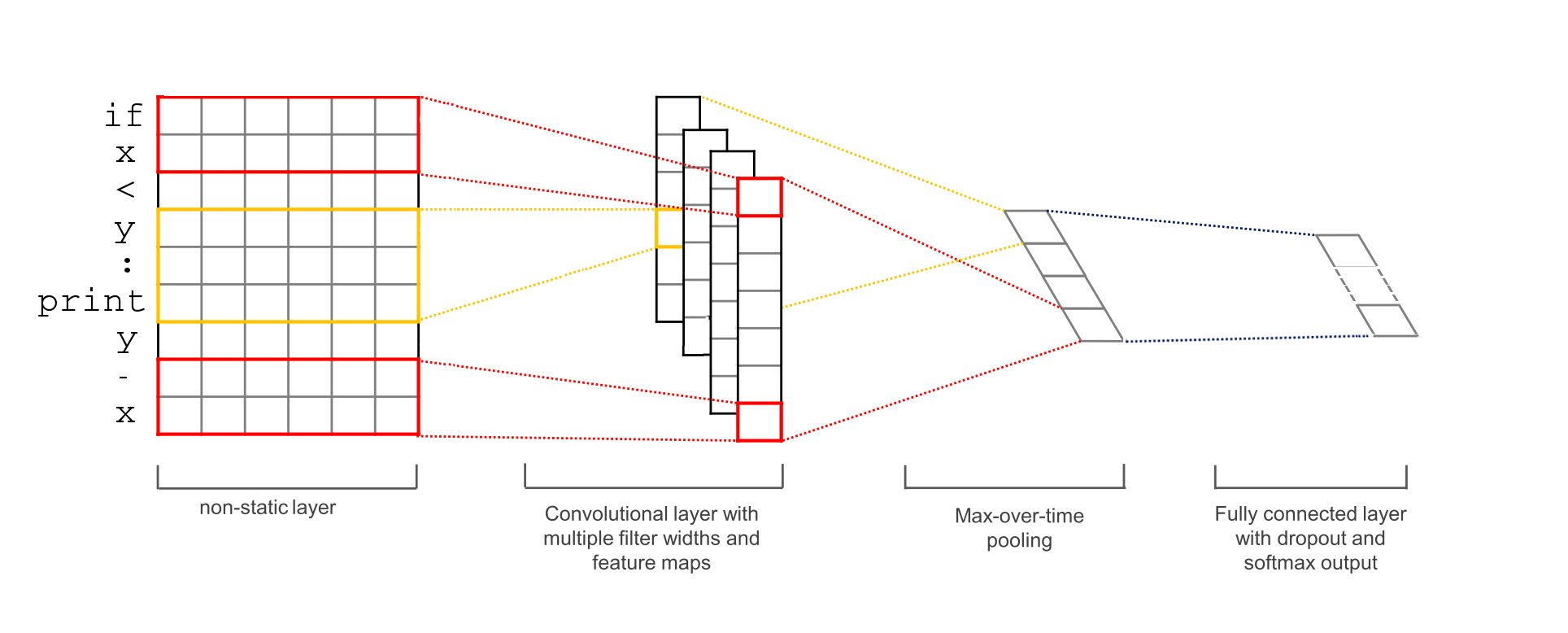
Figure 3 - Convolutional Neural Network model (Figure based on [2])
Results
We performed a test over a 10% data split and calculated the accuracy, precision, recall and f1-score for each label. The overall results for accuracy, precision, recall and f1-score are 97%, 96%, 96 and 96% respectively. The per-label performance scores are also quite high (Chart 3). Chart 3 - Results per class
So the results look good, but let’s take a look at prediction explanations to check how the classifier is making its decisions. We used LIME to generate “explanations” which highlight words that are most correlated with each label. This way, we have an idea why the model is choosing one label instead of another.
A Scala snippet:
object HelloWorld {
def main(args: Array[String]) {
println("Hello, world!")
}
}
Result with explanations:

A Java snippet:
BufferedWriter out = null;
try {
out = new BufferedWriter(new FileWriter("filename", true));
out.write("aString");
} catch (IOException e) {
// error processing code
} finally {
if (out != null) {
out.close();
}
}
Explanations:

An OCaml snippet:
# let average a b =
let sum = a +. b in
sum /. 2.0;;
val average : float -> float -> float =

Future directions
Although the classifier performance is very high, there are still ways to improve the results. For instance, trying a character-level model which learns directly from characters without the need for a word embedding layer [4]. Also, versioned data for each programming language could be obtained to make it possible to assign a specific version to a source code snippet.
References
- Githut - http://githut.info/
- Kim, Y. (2014). Convolutional Neural Networks for Sentence Classification. Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP 2014), 1746–1751.
- Wang, P., Xu, J., Xu, B., Liu, C., Zhang, H., Wang, F., & Hao, H. (2015). Semantic Clustering and Convolutional Neural Network for Short Text Categorization. Proceedings ACL 2015, 352–357.
- Zhang, X., Zhao, J., & LeCun, Y. (2015). Character-level Convolutional Networks for Text Classification, 1–9.
Related Content
-
 General
General16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
-
 Product
Product15 Mar, 2023
Introducing an even better Quantexa News Intelligence app experience
Ross Hamer
4 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.