Over the past few years, the phenomenon of clickbait has grown from nothing into a ubiquitous part of the that content we consume. From YouTube videos to news stories, we’ve all gotten familiar with headlines that don’t tell us much about the actual content, but instead promise us an emotional reaction or offer us a list of things we really don't need to know. This can also dilute the insights from your business intelligence solution when your searches for important news content also returns clickbait. For instance, if we want to monitor news about Narendra Modi'senvironmental policy, we might be returned this piece that isn't relevant to it at all:
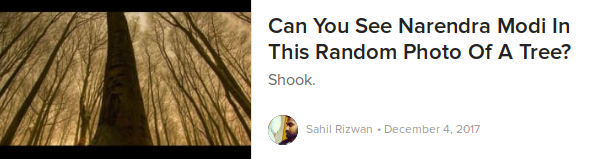
And here’s a problem if you want to ignore clickbait: it’s getting more mainstream. Previously you could just avoid well-known clickbait sites like Buzzfeed or Upworthy, but as ridiculous as it used to seem, mainstream news outlets are adopting clickbait too:

So if you want to ignore clickbait, you can’t just avoid certain websites, you need to look at every individual headline, and filter out all of the annoying ones wasting your time. At AYLIEN, we provide the Natural Language Processing tools that help people to build whatever they dream up or to solve problems in innovative ways. So we spent an hour using our Text Analysis Platform to build a classifier that can tell if a headline is clickbait or not. With this classifier, we can then filter data from our News API to create our own, clickbait-free news feed, no matter topic or source we look at - problem solved! Here’s a demo for you to test this model out. To use it, think of a single event and then try out clickbait and non-clickbait headlines to describe it. For example, compare “Trump proposes a wall at the border” with “You won’t believe what Trump has proposed for the border”.
Clickbait Model Demo
Query the Model
Prediction:*We recommend you use this demo on Chrome for best performance This is how TAP works - after we train our classifier on text content that we have labeled, it can look at new data and accurately predict new data. In TAP, there are public classifiers that can classify “sensational” or “factual” news content, recognize offensive speech, and classify JIRA tickets. You can see them all at tap.aylien.com/explore. For the rest of this blog, we’re going to walk you through how we built this classifier. Specifically, we’ll show you how to:
- Gather samples of clickbait and non-clickbait headlines as a Dataset.
- Train a custom TAP Model on this Dataset.
- Deploy the Model and make calls to it as your own private API.
Since TAP is in Beta, training and testing your Model is free, you’ll only need to pay if you want to deploy it as a private API. So let’s jump in!

1. Gathering samples of clickbait & non-clickbait headlines
To train a model to recognize clickbait news headlines, we need to provide it with samples of both clickbait and non-clickbait headlines, with every sample labelled accordingly with either “Clickbait” or “Not Clickbait”. This will allow your Model to recognize linguistic patterns that are specific to each. Luckily, other people have tried to solve this problem before and they made their dataset public: this is a great dataset of 16,000 clickbait headlines and 16,000 non-clickbait headlines that we can use. Once you download both the clickbait and non_clickbait .gz files, use an unzipper like 7zip to extract the data. Then you can open the text files up and see the headlines that your Model will be trained on.Gathered over 2016 from clickbait sites like Buzzfeed and Upworthy, and non-clickbait sites like The Guardian and The New York Times, you can see that the clickbait headlines certainly fit the bill:

Glancing at the data, we can already see some features that are common in clickbait: numbered lists (“17 times…” “32 cute things….”), questions (“What’s a quote or lyric that best describes your depression?” “Are you more Walter White or Heisenberg?”), and the words “this” and “if” seem to be very common. Your Model will learn by noticing details like this during training. When we compare this to our non-clickbait samples, you can see that it’s tougher to define what makes something “not clickbait”:
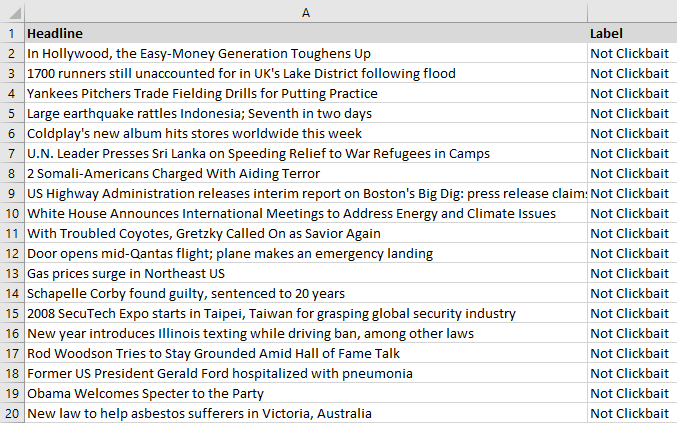
There is no clear feature that is common to all of these headlines, other than that the sentences are all quite declarative. Again, your Model will pick up on this trend, so if you supply it with simple, declarative sentences, it will probably predict ‘Not Clickbait’.
2. Train a Custom Model to recognize clickbait
Now that we have our samples of clickbait and non-clickbait headlines, we can train our Model to classify new headlines as ‘Clickbait’ or ‘Not Clickbait’. To do this, we’re going to use our Text Analysis Platform, or TAP. TAP makes building a custom classification model easy - we can train, test, and deploy a Model all within a browser, and then make calls to our own private API. To get started building a model in TAP, we need to upload the two files that comprise our dataset. This is as simple as clicking Create a Dataset and creating two folders in that dataset - one named “Clickbait” and the other named “Not Clickbait”. In each one of these folders, we simply right click on the folder and upload the correct file that we downloaded in the previous step.
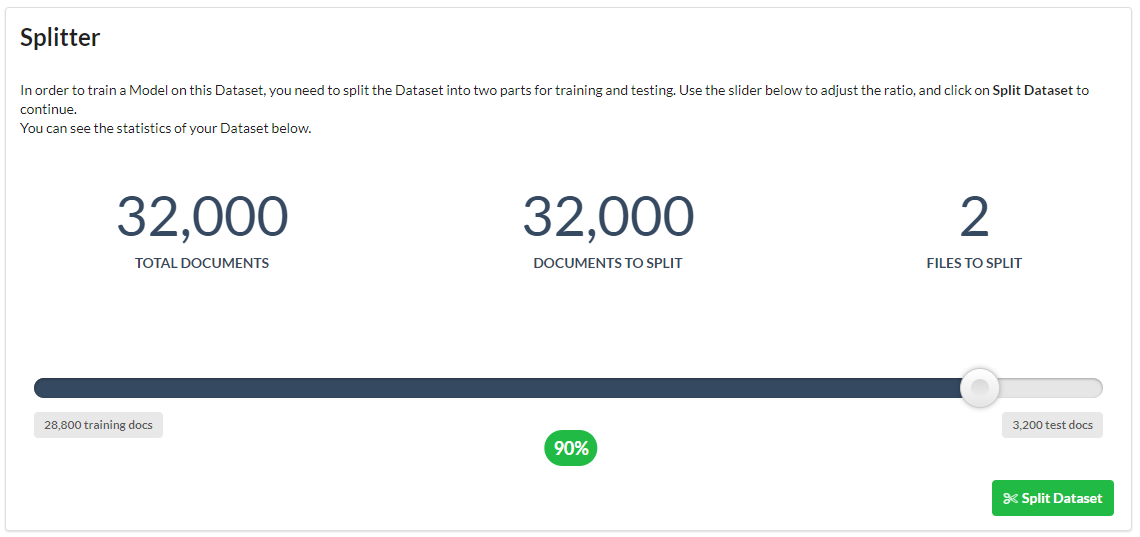
The last thing you need to do with your Dataset is to split it. Splitting your data determines how much data your Model will be trained on, and how much data will be held back to evaluate how accurate your Model is after it has been trained. For most cases, a 90:10 ratio of training to test data is suitable. Move the slider into the correct place:
After this, we can move to the next step in the process, where you actually build our Model by training it on the Dataset you just uploaded to TAP. To do this, just click on the Next Step button, which will offer you two options on how to optimize the Model-training process - for news-style content or social media-style content. In this case, we’re actually going to optimize for social media-style content here, since headlines on their own are more similar to Tweets and Facebook posts than full news articles. You can also tweak the parameters manually if you click Advanced Parameters, but we’re not going to do this in this walkthrough.
Once you’ve selected social media content and clicked Next Step, TAP will begin training your Model. With a Dataset of 32,000 documents, training a Model will usually take around a minute.
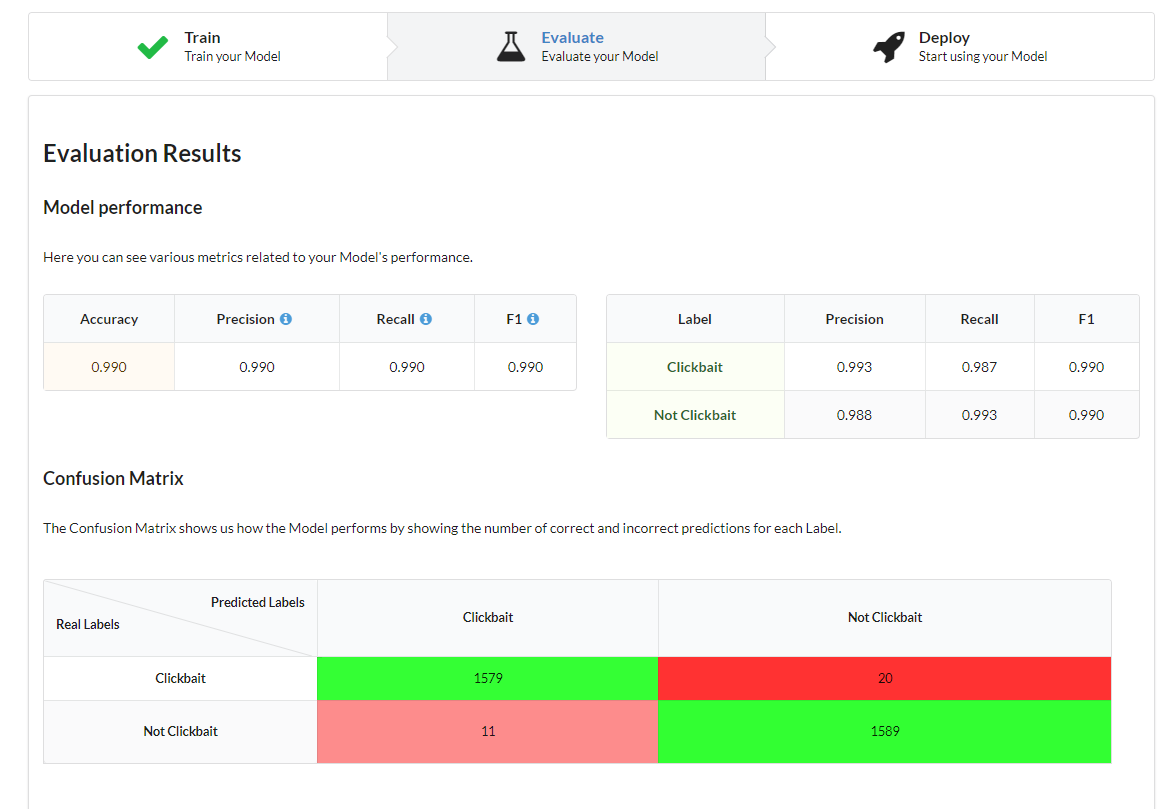
Once your Model is finished training, it will be evaluated on your test data and you will be shown the results. As you can see below, the Dataset we used created a very accurate Model, with an F1 score of .990 (1 is perfect).
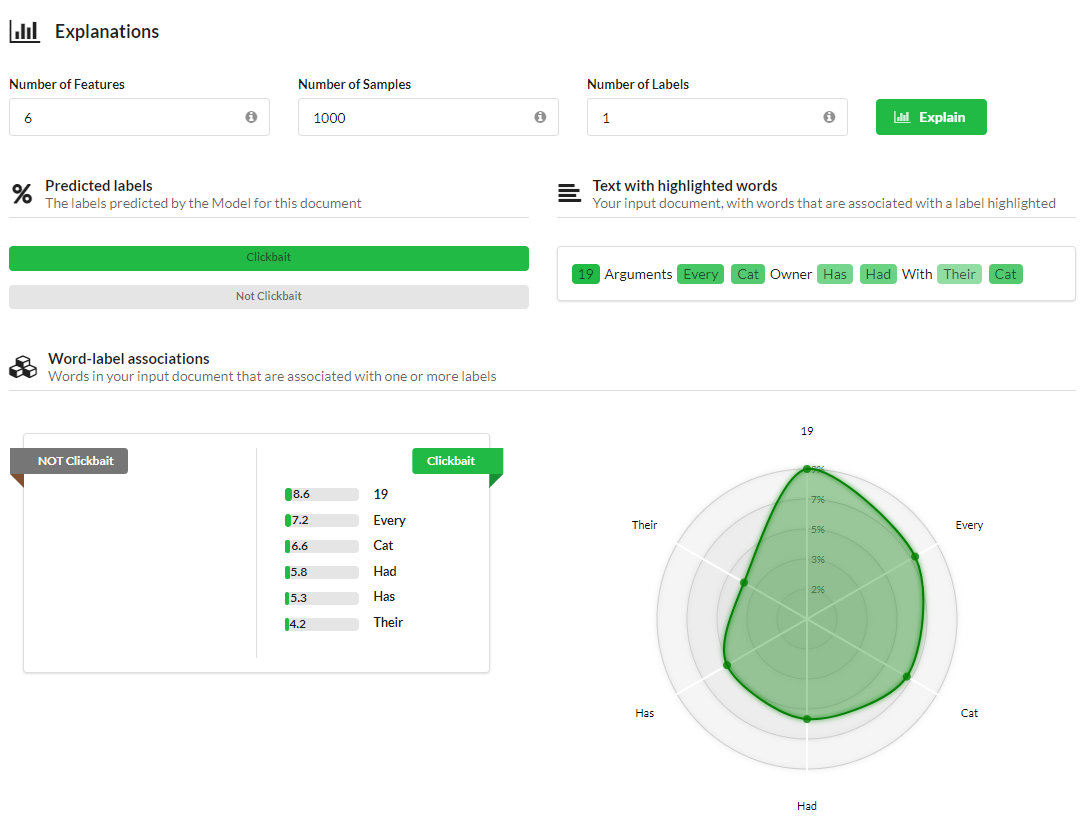
If you want to get some insight into how the Model makes its predictions, take a look at the Live Evaluation section of the Evaluate page. This is where you can see which words influenced your Model to make every prediction. You can see in the example below, “19 Arguments Every Cat Owner Has Had With Their Cat,” our Model has predicted the “Clickbait” label. In the Text With Highlighted Words section, we can see which words influenced this prediction the most. “19,” “Every,” and “Cat” are the biggest predictors of the “Clickbait” label in this sentence.
So now that we’ve built a fully-functional, custom NLP Model, all that’s left to do is to deploy it, which we do by clicking the Next Step button to move to the deployment stage of the process.
3. Deploy your Model & make calls to it
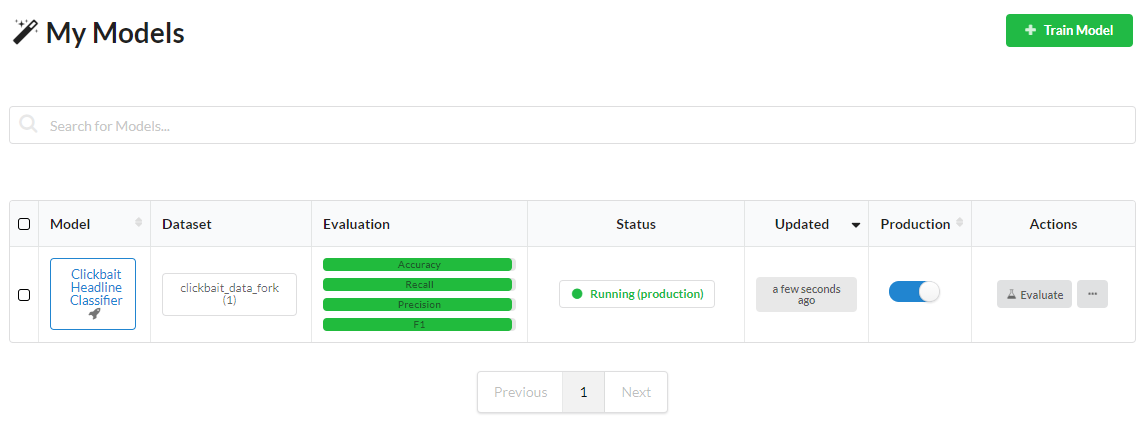
In TAP, deploying a Model to production is just a case of toggling the Production button on the My Models page. This takes your Model from the sandbox and deploys it into production where you can make calls to it like any other API.
At this point, you’ve built and deployed your Model, and you’ll want to start making calls to it, which is really easy. You just include your Model’s endpoint, your API key, and the text you want to analyze as a POST request. Tosign up to TAP free of charge, click on the image below:

Related Content
-
 General
General16 Feb, 2024
Why AI-powered news data is a crucial component for GRC platforms

Ross Hamer
4 Min Read
-
General
24 Oct, 2023
Introducing Quantexa News Intelligence
Ross Hamer
5 Min Read
-
 Product
Product15 Mar, 2023
Introducing an even better Quantexa News Intelligence app experience
Ross Hamer
4 Min Read
Stay Informed
From time to time, we would like to contact you about our products and services via email.